Pekiştirmeli Öğrenme ile Adaptif Dövüş Robotu Eğitimi
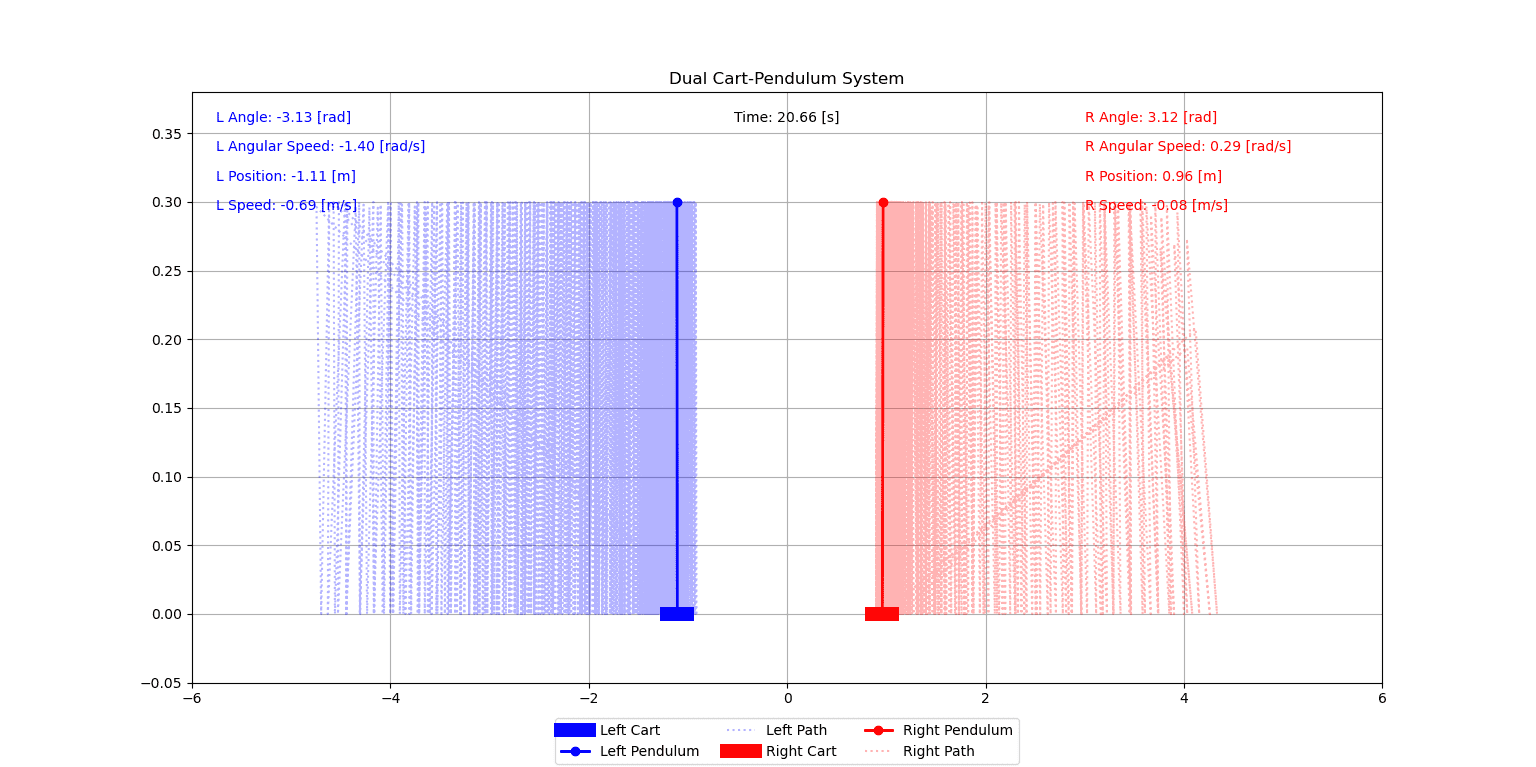
Ters sarkaç (inverted pendulum) fizyonomisiyle modellenen bir sistemin, harici kontrol modellemelerine gereksinim duymadan (model-free) denge ve dış müdahale reaksiyonu geliştirmesi Deep Q-Network mimarisi ekseninde değerlendirilmiştir. Temel benchmark referansı olan lineer kontrol (LQR) ile başlayıp sıralı zorluk artışına dayanan 4 fazlı bir tasarım çerçevesi izlenmiştir. Ajanın kendi kopyalarıyla kapalı döngüde rekabet etmesi (self-play), tek optimizasyon ekseninde ortaya çıkan aşırı güven (overconfidence) yanılgılarını sınırlandırmak için uygulanmıştır.
⚠️ PoC Projeleri İçin: Self-play mimarisiyle hesaplanan ajan profili, deterministik bozucuların bulunduğu test ortamlarında standart analitik verilerle ayarlanan ajanlara (LQR referansları) kıyasla matematiksel olarak daha tutarlı bir hata toleransı (robustness) sağlama potansiyeline sahiptir.
Proje Künyesi
|
Parametre |
Değer |
|---|---|
|
Kategori |
Çözüm Mühendisliği |
|
Teslimat Tipi |
Akademik Araştırma |
|
Durum |
Proof of Concept |
|
Rol |
Control Systems Researcher |
|
Ölçek / Kapsam |
4 Fazlı Eğitim Pipeline’ı, Self-Play Adversarial Training |
Mevcut Durum ve Sorun
Bağlam: Ters sarkaç sistemleri yapısal olarak kararsız fiziksel sistemlerdir. Dışarıdan mekanik bir müdahale (rekabet) senaryosu gerektiren durumlarda, stabilizasyon ile reaktif hamle planlamasının aynı anda koordine edilmesi problemin boyutunu karmaşıklaştırır. Kritik Sorunlar: Sistem denklemlerinin açık olarak varsayılamadığı esnek operasyon alanlarında salt statik limitlere (LQR gibi) dayanan kalibreler yetersiz kalma eğilimindedir. Modelin yalnızca statik kurallar üzerinden optimize edilmesi (overfitting), dinamik tehditler altında overconfidence sonucu çöküş reaksiyonları gösterir.
|
Problem |
Detay |
|---|---|
|
Yapısal Kararsızlık |
Ters sarkaç modelinin sürekliliği için bitmeyen kapalı-döngü geri besleme ihtiyacı |
|
Çoklu Optimizasyon |
Cihazın kendi ağırlık merkezini koruması ve eşzamanlı pozisyonlama hesabı yapması |
|
Tanımsız Model |
Dışarıdan sağlanan hazır bir dinamik sistem transfer fonksiyonunun varsayılmaması |
|
Overconfidence Zaafiyeti |
Statik algoritmaların öngörülemeyen deterministik olmayan etkilere olan zayıf toleransı |
Çözüm Mimarisi ve Aksiyon
Mimari Yaklaşım: Eksik tanımlı kontrol ortamlarında oluşabilecek güven sapmalarını (overconfidence) analiz etmek amacıyla, değişken zorluk eğrisi taşıyan 4 fazlı bir eğitim yapısı kurgulanmıştır.
Uygulanan Metodoloji:
Faz 1: Referans Veri Çıkarımı (LQR Simülasyonu)
Amaç: Karşılaştırmalı testler platformu kurmak için temel sistem dinamiklerini haritalamak ve baz yanıtları kaydetmek.
- Dış kütüphane fonksiyonlarına bağımlı olmadan yalın bir LQR kontrolcü bloğu geliştirildi.
- CTMS Michigan modeli temel alınarak özelleştirilmiş test fizik motoru hesaplandı.
- Formüle edilen çıktı matrisleri (state → action) referans model benchmarkı olarak arşivlendi.
Faz 2: Bireysel Stabilizasyon
Amaç: Sistemin hazır bir girdi haritası (supervised learning) kullanmaksızın kendi hata fonksiyonlarıyla stabil kalma yeteneğini optimize etmesi.
- Deep Q-Network (DQN) ağ mimarisine geçiş yapılarak eğitim parametreleri atandı.
- Hesaplama kararlılığını sağlamak için Experience Replay ve Target Network gecikme döngüleri kullanıldı.
- Kısıt mekanizmaları uygulanarak (Reward Shaping): Açının hedef eksenden sapması, eksenel pozisyon hatası ve moment sarfiyatı hesaplanarak sistem filtrelendi.
Faz 3: Gürültü ve Saldırı Dayanıklılığı
Amaç: Kararlılığı test etmek için simülasyon ortamında fiziksel anomalilerin devreye alınması ve eylem uzayının (action space) ikiye ayrılması.
- Deterministik olmayan rastgele darbeler için Poisson dağılımı temelli ek dış kuvvetler (disturbance) yaratıldı.
- Sistem bu süreçte hem mekanik dengeyi muhafaza edip hem de planlı hareket sergileme parametrelerini ağırlıklandırdı.
- Temel “Balance force” değişkeni ile “Attack force” değişkeni bağımsız uzaylarda işlendi.
Faz 4: Modelin Kendi Kendine Dövüşmeyi Öğrenmesi
Amaç: İzole eğitimlerde oluşan overconfidence toleransının karşılıklı baskı altında test edilmesi işlemi.
- Ağda ölçüm standardı sağlamak için iki farklı ajan profili aynı neural network başlangıç ağırlıklarından (weights) türetildi.
- Eğitimin her bir periyodunda iki modül de kendi dengesini hesaba katarken diğer modülün denge fonksiyonunu zorlama mantığını yürüttü.
- Modüller statik bir fonksiyon parametresi yerine dinamik ve kendi tepkisine karşılık veren kopyasıyla simetrik olarak çapraz değerlendirmeye girdi.
Mimari Karar: İki bağımsız sinir ağı bloğu kullanılması kısa eğitim sürelerinde senaryo limitleri içinde “model dominance” olarak adlandırılan asimetrik üstünlük sapmalarına neden olmuştur. Ortak sinir ağı (YSA) topolojisine geçilerek bu hesap karmaşası dengelenmiş ve asimetrik sapmalar limitlere çekilmiştir.
İki Modlu İşletim Şartları:
- İzole Mod: Eğitim döngüsünün başlarında ortamda rekabet parametreleri inaktif olup sadece kartezyen denge izlemeye alınır.
- Kombine Mod: Parametreler belli bir olgunluğa geldiğinde denge vektörleri ile eş zamanlı olarak saldırı politikaları da (Q-Values) aktifleştirilir.
Sistemdeki kontrol kaosunu önlemek adına saldırı eylemlerini ifade eden limit tavanı, denge fonksiyonlarına ait limitlerin ~%15’i oranında tutulmuştur. (Denge Toleransı: [-10, +10] N, Saldırı Toleransı: [-1.5, +1.5] N).
Sonuçlar ve Operasyonel Kazanımlar
|
Odak |
Tespiti Yapılan Etki |
|---|---|
|
Eşzamanlı Optimizasyon |
Mekanik stabilizasyon eğrileri ile reaksiyon yönlendirme işlemleri aynı süreç içerisinde değerlendirildi. |
|
Overconfidence Etkileri |
Self-play ağırlık güncellemeleri tatbik edilerek kapalı devre statik sistem varsayımlarının (aşırı güven) neden olduğu hatalar sınırlandırıldı. |
|
Sistem Dayanımı (Robustness) |
Adversarial baskı senaryolarında, klasik analitik hesaplamalı LQR referansına kıyasla daha sürdürülebilir esneklik limitleri çıkarıldı. |
|
Model Değişkenliği |
Formüle edilmiş nihai ve ideal sistem denklemleri dışarıdan girilmeden kontrol çıktıları saptandı. |
Test Sonuçları
|
Metrik |
Değer |
|---|---|
|
Test Bölüm Sayısı |
300 Episode |
|
Ortalama Simulasyon Süresi |
~320 Frame/Adım |
|
Gözlemlenen Tavan Seviye |
700 Frame/Adım |
|
Keşif (Exploration) Çarpanı |
0.0 Test Epsilon |
Simülasyon Görselleri

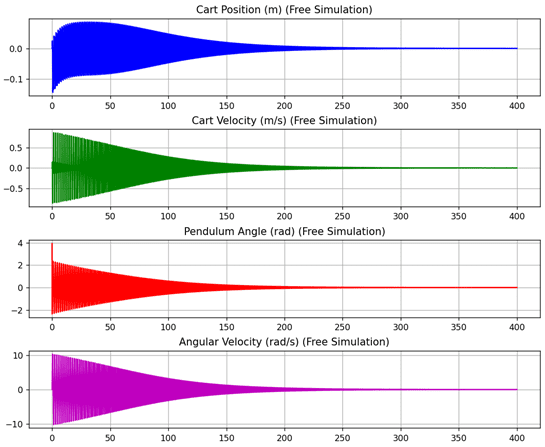
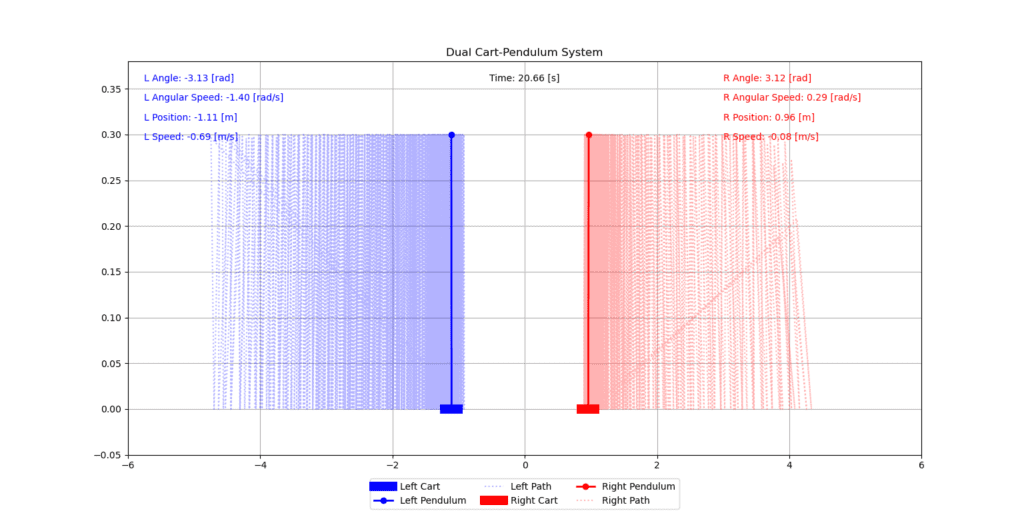
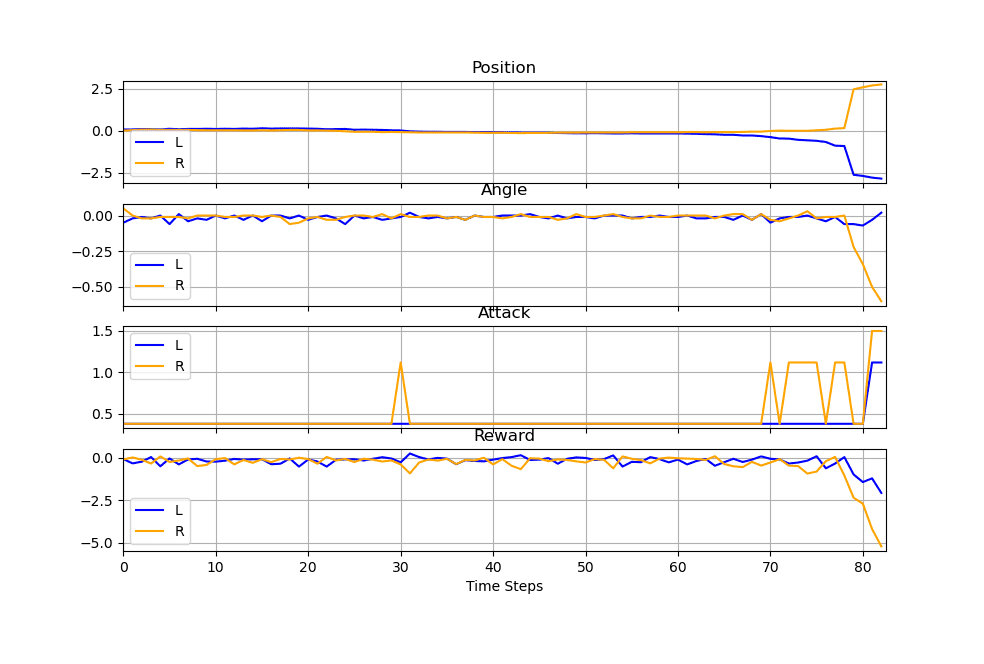
Demo: Self-Play Mücadele Simülasyonu
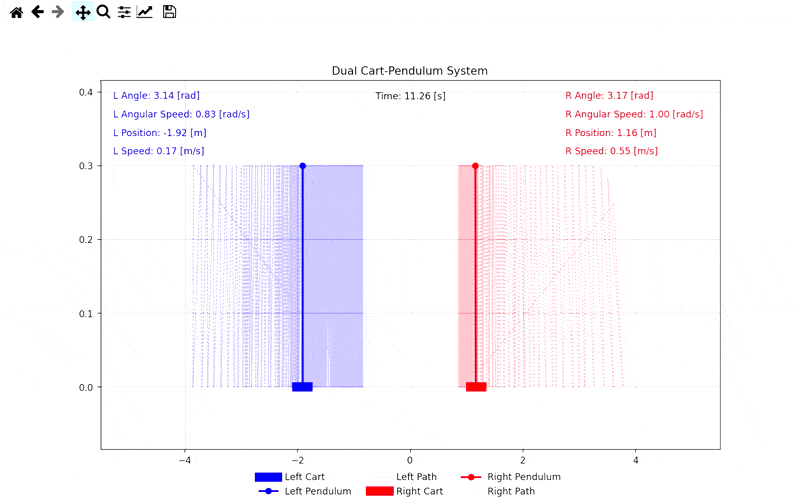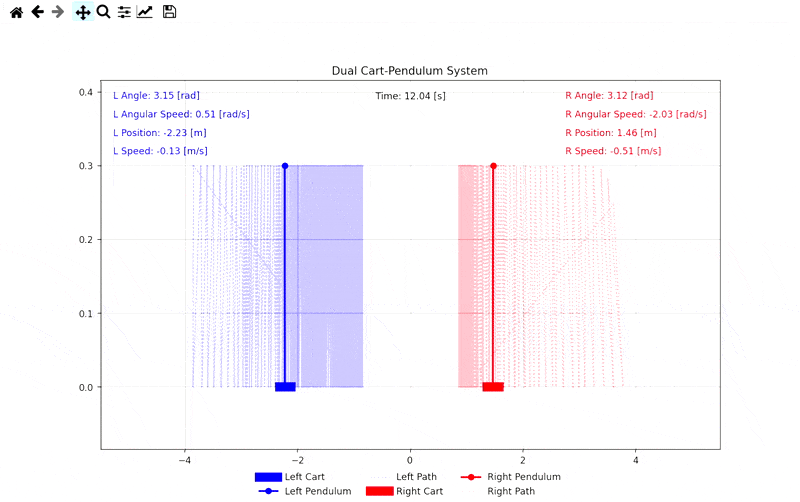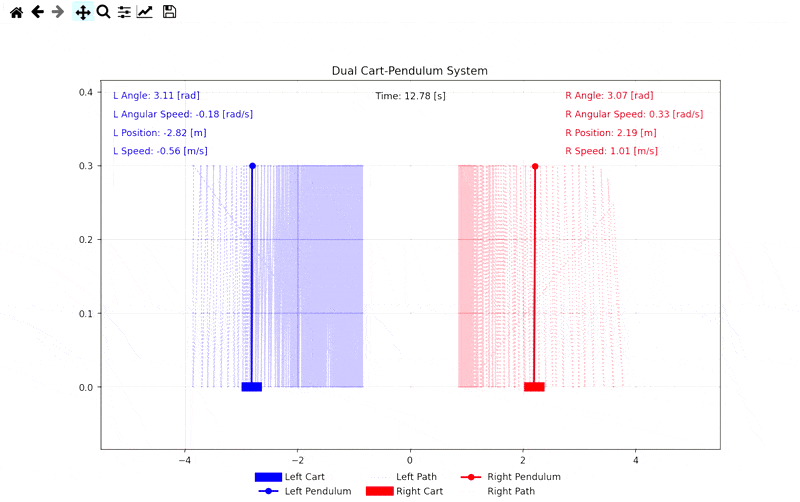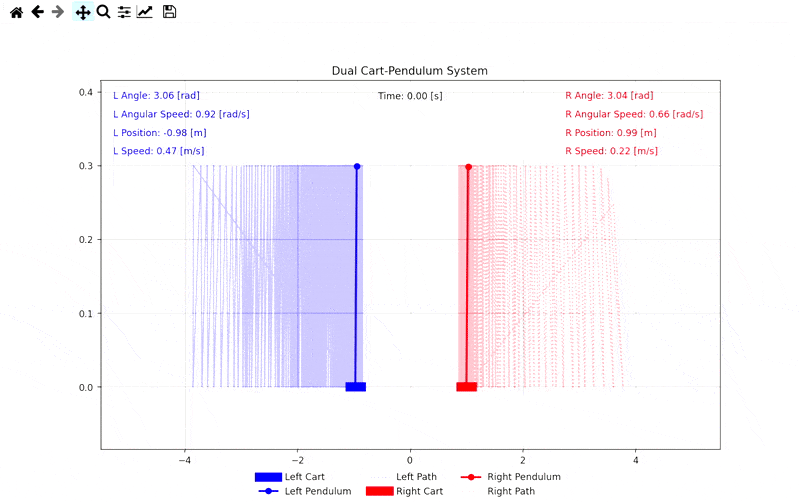
İlgili Bağlantılar
🔗 İlgili Yazı: Doğrusal Olmayan Sistemlerde Kontrol Stratejileri: LQR ve Deep RL Karşılaştırması
📄 Kaynak Makale PDF: Makina Öğrenmesi Teknikleri Kullanılarak Bir Dövüşen Robotun Eğitilmesi
📂 Kaynak Kodu: Github/neural-adaptive-control-simulation
Bu araştırma, İTÜ Kontrol ve Otomasyon Mühendisliği programı kapsamında yapılmış ve “Makine öğrenmesi teknikleri ile uyarlanabilir eğitim mimarileri” başlığı altındaki bitirme projesi çalışmalarında sunulmuştur.
Son Güncelleme: Ocak 2026