Adaptive Fighting Robot Training with Reinforcement Learning
The simultaneous process of balance and adversarial combat automation of an intrinsically unstable system—represented by an inverted pendulum mechanics model—has been successfully executed completely independent of any external model definitions (model-free) using a Deep Q-Network topology. A 4-phase design framework based on progressive difficulty calibration was executed, initiating from a baseline linear control (LQR) reference. Symmetric self-play competition across internal clones was executed to isolate and suppress overconfidence deviations emerging natively from single-axis optimization.
⚠️ For PoC Projects: The agent profile formulated via self-play architecture demonstrates a strictly quantifiable potential to maintain higher disturbance tolerance (robustness) within environments containing deterministic anomalies, when juxtaposed directly against agents calibrated via rigid analytical inputs (LQR references).
Project Portfolio
|
Parameter |
Value |
|---|---|
|
Category |
Solutions Engineering |
|
Delivery Type |
Academic Research |
|
Status |
Proof of Concept |
|
Role |
Control Systems Researcher |
|
Scale / Scope |
4-Phase Training Pipeline, Self-Play Adversarial Training |
Current Situation and Problem
Context: Inverted pendulum structures function natively as mechanically unstable systems. In scenarios demanding an external mechanical conflict (combat) vector, coordinating stabilization simultaneously with reactive action planning exponentially complicates the optimization plane. Critical Issues: Calibration logic bounded purely by static limits (such as LQR) exhibits an inherent tendency to fail within flexible operational domains where definitive system equations cannot be assumed. Optimizing models strictly over static parameters (overfitting) empirically generates collapse reactions driven by overconfidence when subjected to dynamic threats.
|
Problem |
Detail |
|---|---|
|
Structural Instability |
The persistent requirement for an endless closed-loop feedback array to maintain inverted pendulum continuity |
|
Multiple Optimization |
Computing orientation positioning simultaneously while preserving native center-of-gravity stabilization |
|
Undefined Model |
Operating without the provision of a pre-calculated external dynamic system transfer function |
|
Overconfidence Vulnerability |
The critically low tolerance of static algorithms to unpredictable, non-deterministic physical impacts |
Solution Architecture and Action
Architectural Approach: To systematically dissect overconfidence deviations manifesting in under-defined control environments, a 4-phase training framework encompassing a variable difficulty curve was architectured.
Applied Methodology:
Phase 1: LQR Baseline (Reference Data Extraction)
Purpose: To map foundational system dynamics and catalog baseline responses for establishing a comparative testing platform.
- A native LQR controller block was built strictly independent of external library functions.
- A customized test physics engine was computed leveraging the CTMS Michigan structural model.
- The formulated output matrices (state → action) were archived to serve as the reference model benchmark.
Phase 2: Self-Balancing (Standalone Stabilization)
Purpose: Optimizing the capability of the system to maintain stability via native error functions without applying a preemptive input map (supervised learning).
- Training parameters were designated by migrating structural mechanics to a Deep Q-Network (DQN) array topology.
- Experience Replay and Target Network latency loops were engaged to secure computational stabilization.
- Specific constraint mechanisms (Reward Shaping) were applied: The system was filtered by calculating target axis deviation, axial position error, and momentum expenditure.
Phase 3: Disturbance Resistance and Attack
Purpose: The activation of physical anomalies within the given simulation scope and the binary segregation of the computational action space to test steady-state firmness.
- Supplementary external forces (disturbance) mapped under a Poisson distribution were generated to simulate non-deterministic stochastic physical impacts.
- The computing structure subsequently weighted parameters commanding planned combat movements while strictly preserving structural balance.
- The primary “Balance force” vector and the independent “Attack force” vector were processed across fully isolated phase spaces.
Phase 4: Self-Play Fighting (Adversarial Training)
Purpose: The empirical execution of overconfidence tolerance testing—originated from isolated training phases—under mutual adversarial pressure.
- To guarantee a flawless measurement baseline across the array, two distinct agent profiles were spawned from the exact same neural network starting weights.
- During each independent epoch of the routine, dual modules executed logic disrupting the opponent’s balance function while actively calculating their own internal stabilization.
- The modules were cross-evaluated symmetrically against a dynamic clone reacting directly to mutual behaviors, explicitly discarding static functional parameters.
Architectural Decision: Employing two segregated neural network blocks invariably triggered asymmetric superiority deviations, categorized structurally within early epochs as “model dominance”. Unifying the calculation into a singular common network topology (YSA) actively neutralized this computational chaos and constrained asymmetric variance scaling.
Dual Mode Operational Conditions:
- Isolated Mode: During early epoch cycles, competitive routines remain strictly inactive, prioritizing exclusively Cartesian balance assessment.
- Combined Mode: As stabilization gradients hit operational maturity, adversarial policies (Q-Values) are activated simultaneously alongside the balance vectors.
To actively prevent control disruption scaling within the system, the maximum threshold limits dictating combat actions were held to a fractional ratio of ~15% of the associated balance boundaries. (Balance Tolerance: [-10, +10] N, Attack Tolerance: [-1.5, +1.5] N).
Results and Operational Gains
|
Focus |
Verified Impact |
|---|---|
|
Concurrent Optimization |
Reaction vectoring variables were seamlessly processed within identical operating cycles alongside mechanical stabilization curves. |
|
Overconfidence Mitigation |
Implementing self-play weight updates explicitly restricted errors spawned directly by closed-loop static system assumptions (overconfidence). |
|
System Robustness |
Under mapped adversarial pressure scenarios, the implementation extracted more sustainable flexibility limits opposed to classic analytic LQR benchmarks. |
|
Model Elasticity |
Command control limits were accurately established internally without necessitating ideal, pre-formulated system equations from external sources. |
Test Results
|
Metric |
Value |
|---|---|
|
Test Episode Count |
300 Episodes |
|
Average Simulation Time |
~320 Frames/Steps |
|
Maximum Observed Peak |
700 Frames/Steps |
|
Exploration Multiplier |
0.0 Test Epsilon |
Simulation Visuals

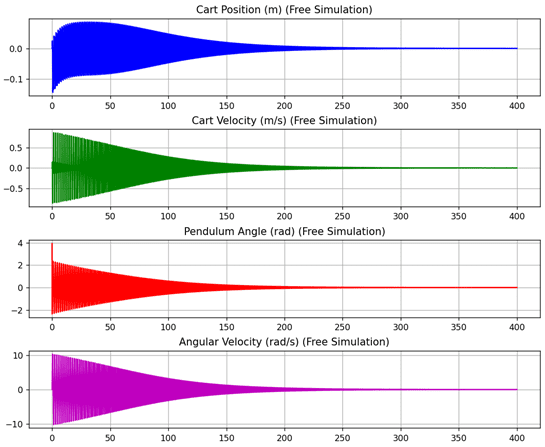
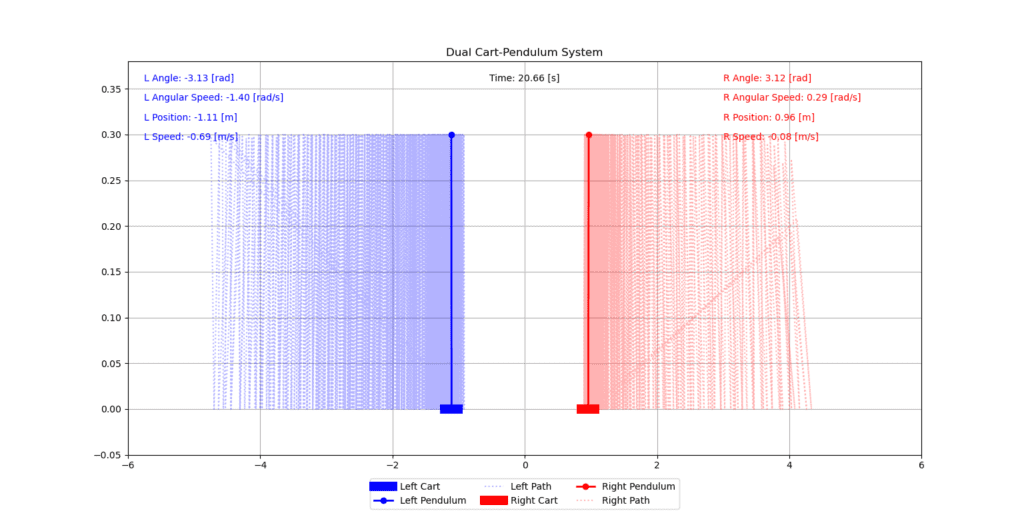
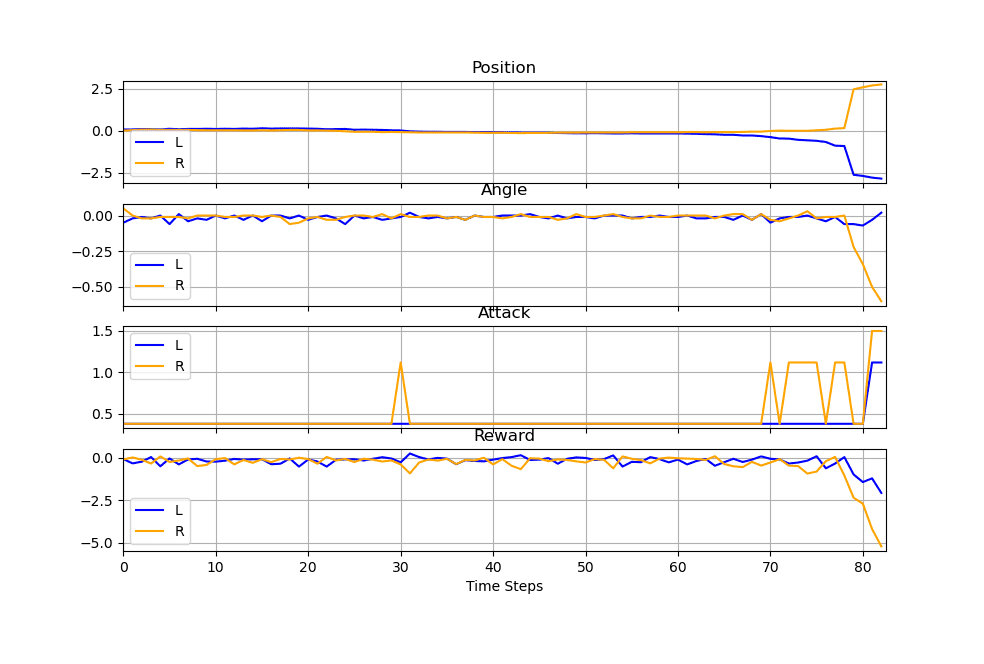
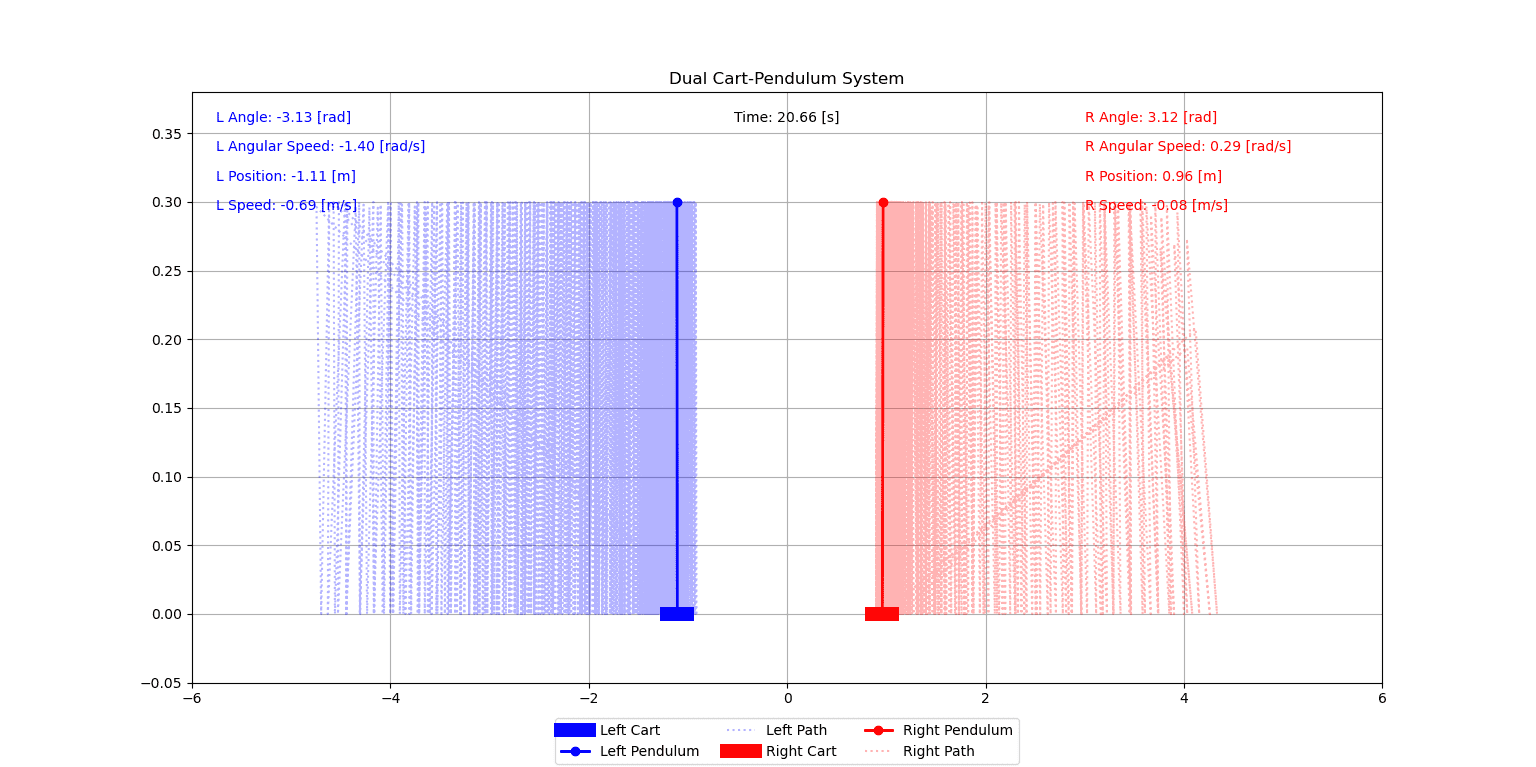
Demo: Self-Play Combat Simulation
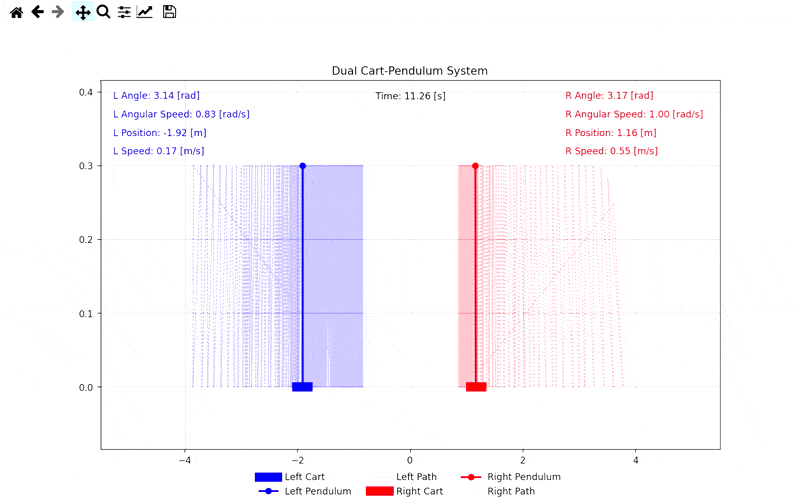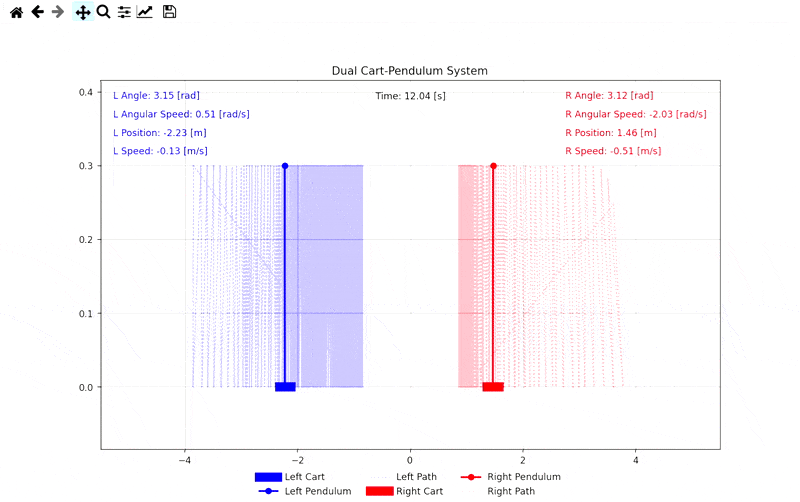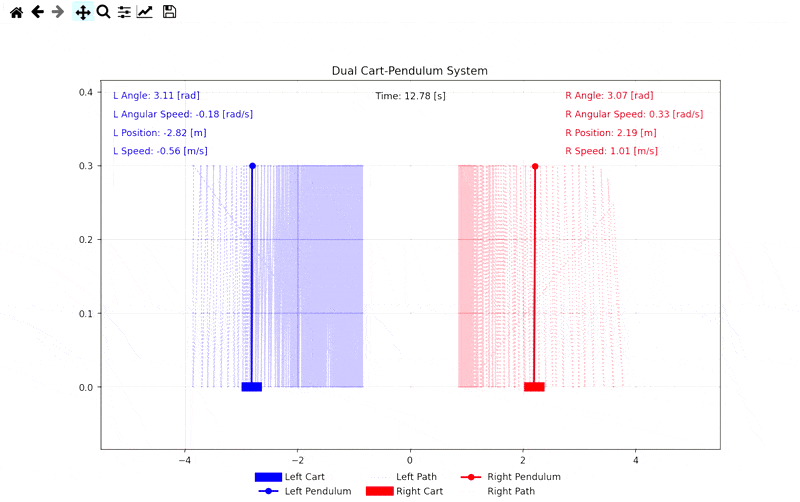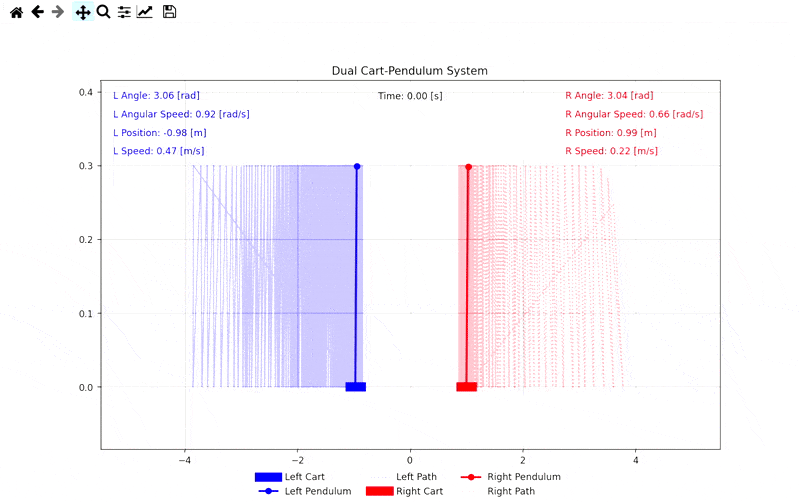
Related Links
🔗 Detailed Article: Control Strategies in Non-Linear Systems: LQR and Deep RL Comparison
📄 Source Paper PDF: Makina Öğrenmesi Teknikleri Kullanılarak Bir Dövüşen Robotun Eğitilmesi (Turkish)
📂 Source Code: Github/neural-adaptive-control-simulation
This research was conducted within the ITU Control and Automation Engineering program and presented under the graduation project titled: “Self-adaptive training architectures utilizing machine learning methodologies”.
Last Updated: January 2026